- English
- 中文
 Photo by Matt Duncan / Unsplash
Photo by Matt Duncan / Unsplash
This article was published on May 1, 2023 by Alan Chan, co-founder of Heptabase, one year after releasing the public beta version of Heptabase.
Foreword
It has been a year and a half since I last published a My Vision article. The reason it took me so long to write this article today is because I believe that only after interacting extensively with real-world users can I see more clearly the vaguer parts of my vision. Therefore, over the past year and a half, the Heptabase team has been building products, talking to users, and validation our hypothesis through continuous iteration.
In the conclusion of the previous article, I described Heptabase’s vision as follows:
In short, from the perspective of “The lifecycle of human knowledge work,” we are building an ecosystem of tools to help knowledge workers integrate their knowledge lifecycle of exploring → collecting → thinking → creating → sharing. Our guiding principle is to optimize information interoperability, context retrieval, and collective knowledge creation, with the ultimate aim of evolving a contextualized knowledge internet.
This way of describing the vision has the advantage of providing a framework for the knowledge lifecycle to guide our product development, as well as three major principles to be aware of in execution. However, for a general audience, there are still many questions after reading this description.
First, although I presented some ideas and directions for information interoperability, context retrieval, and collective knowledge creation in the previous article, I did not delve deep into our roadmap at the execution level.
Second, the description of this vision is relatively abstract and academic, and after reading it, you may still be a bit confused: why do we need a new knowledge internet? What benefits can preserving the context of ideas bring us? What primitive human need does Heptabase’s knowledge internet want to solve?
In this article, I will delve deeper into these questions that were not answered clearly in the previous article, clarify Heptabase’s core goals, and let Heptabase users better understand our roadmap.
Purpose
Before discussing the roadmap, I want to rephrase Heptabase’s vision in a more straightforward way: We want to create a world where anyone can effectively establish a deep understanding of anything.
In the era of information explosion dominated by Google, social media, and ChatGPT, acquiring knowledge has become extremely easy. However, this knowledge is often just the tip of the iceberg in the vast knowledge structure and thinking context of humanity, and most people still have no idea what the actual shape of these icebergs is, nor have their ability to deeply understand complex things significantly improved.
At Heptabase, we believe that the biggest challenge modern people face in learning, researching, and problem-solving is not the lack of knowledge, but the lack of context to connect countless pieces of knowledge and the tools to construct and preserve these contexts. If we can preserve the context of knowledge and let all humanity share these contexts, when others want to learn and research the same knowledge, they can use these contexts to establish a more comprehensive and in-depth understanding.
Based on this vision, I have set four progressive stages for the company’s development. The significance of these four stages is to build an “open hyperdocument system” that can carry our contextualized knowledge internet and build the infrastructure needed for this system layer by layer at each stage. I will discuss the goals and challenges of these four stages in detail and describe this system more completely.
Stage 1 — Contextualize Your Brain
In stage 1, our goal is to create a thinking tool that helps everyone learn and research complex topics. The core task of this tool is to enable users to build thinking frameworks on top of a large amount of information, extract important ideas and knowledge, connect the “collect → think → create” stages of the knowledge lifecycle, and preserve the user’s thinking context for these topics.
From the perspective of the final knowledge internet to be built, the significance of this stage is to create two foundational infrastructures: the contextual layer and the descriptive layer.
Contextual Layer
In Heptabase, the basic unit that carries ideas and knowledge is the card, and the contextual layer is the layer used to preserve the thinking context for these cards, corresponding to Heptabase’s whiteboard function. People who have not used Heptabase may think that the purpose of the whiteboard is visualization just by looking at its appearance, but in fact, visualization is only a means. Its real purpose is to trace each card back to its thinking context in different whiteboards.
For this reason, in the early stages of developing the whiteboard, we did not spend too much time on creating common whiteboard product features such as handwriting, shapes, lines, styles, etc., but focused on developing features related to “preserving thinking context,” such as the reuse of cards in multiple whiteboards, bidirectional linking between cards and the whiteboard, hierarchical structure between whiteboards, grouping and indexing of knowledge cards in the whiteboard, and interaction between card editors and whiteboards.

Descriptive Layer
The second foundational infrastructure to be built in stage 1 is the descriptive layer of the card, which is responsible for adding types and attributes to the card, corresponding to Heptabase’s tag and property functions.
In Heptabase, you can add different tags to cards and specify different properties that can be reused by different tags. For example, I use the tags #research-note-taking and #research-communication to manage the relevant cards for my research in note-taking and communication software. Both tags are related to research and share properties such as document type, insight, and importance.
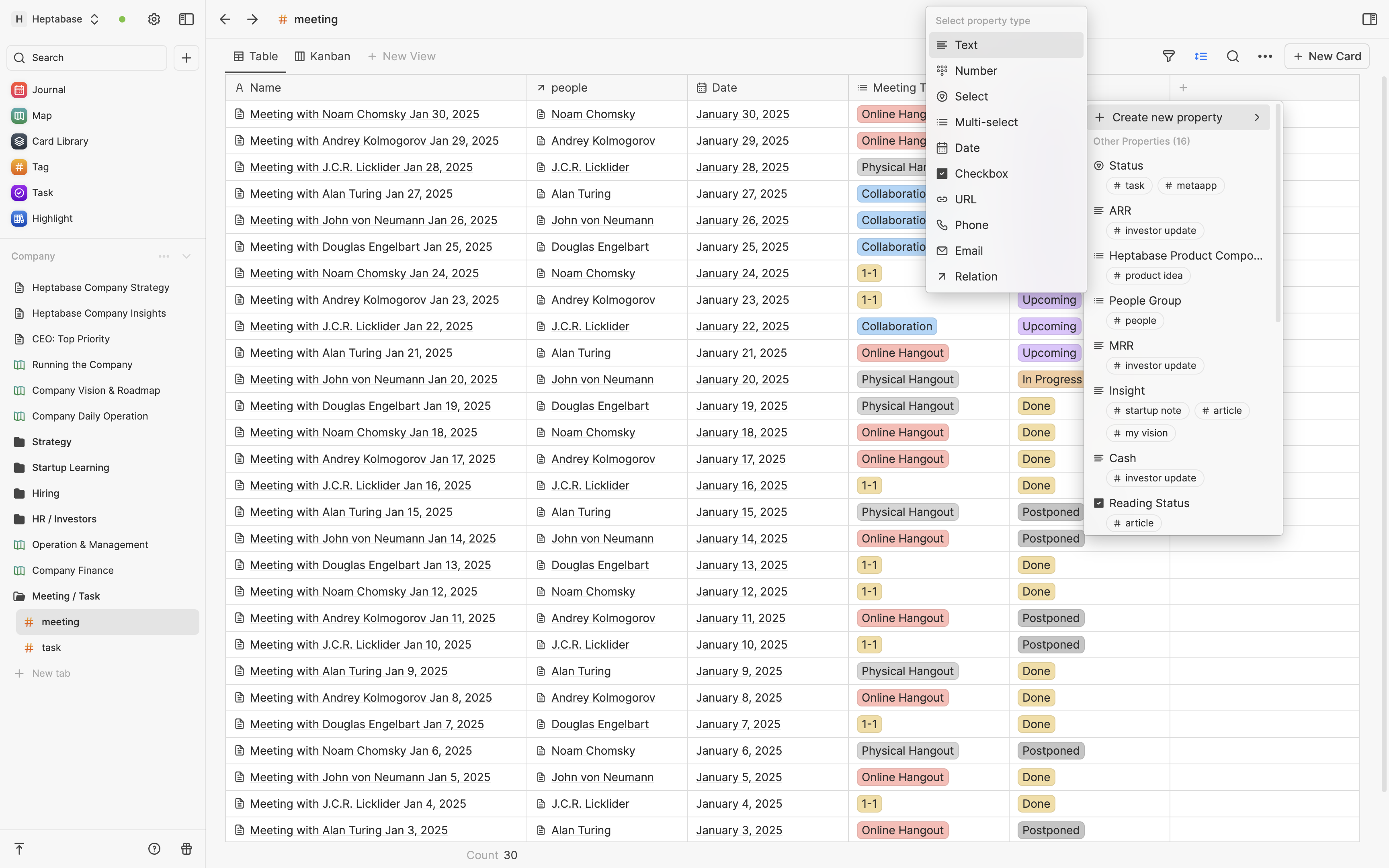
For individual users, such functions can help them better manage homogeneous cards in a database format, and even create different views and filters like common project management systems to view these cards from different perspectives, such as tables and Kanban.
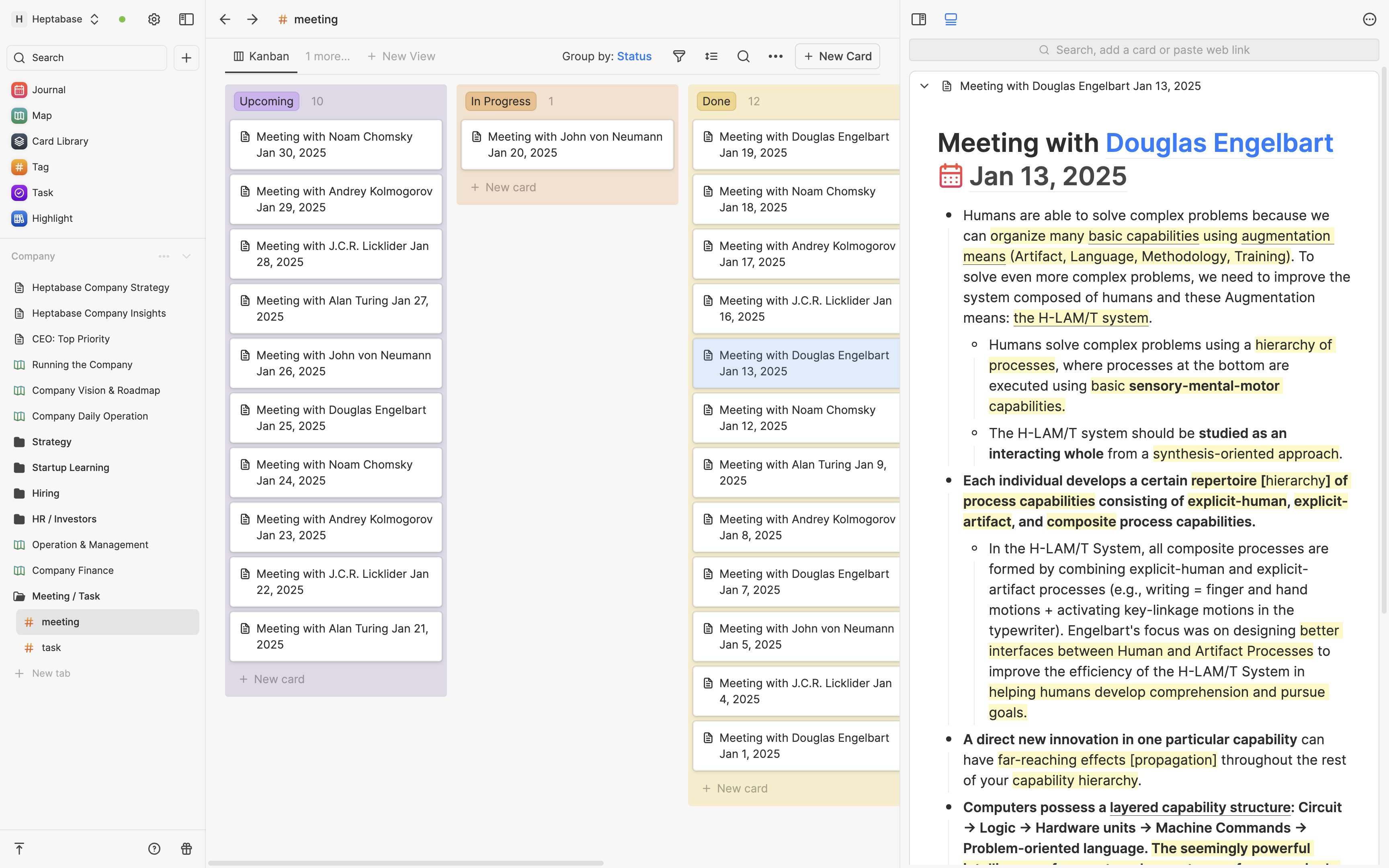
Of course, just as the purpose of the whiteboard is not solely for visualization, the purpose of tags and properties is not solely for card management. Their important long-term purpose lies in stage 4, where third-party developers can build different software for different scenarios based on Heptabase’s card system, thereby expanding the reusability and contexts of these knowledge cards.
Stage 2 — Contextualize Outer Sources
When Heptabase has already built a “good enough” thinking tool in stage 1, we will enter stage 2 to help users not only preserve their own thinking context but also bring external information into this context for thinking, connecting the “explore → collect” stages of the knowledge lifecycle.
From the perspective of the knowledge internet, the significance of this stage is to build two foundational infrastructures responsible for integrating external information into the Heptabase system: the annotation layer and the integration layer.
Annotation Layer
In today’s internet, there is a lot of knowledge saved in different formats such as PDF, video, audio, image, and webpages. If we want to build a knowledge internet that can trace the context of all knowledge, we must bring these different formats of knowledge into our knowledge internet, so that users not only can extract important ideas from them but also trace the sources of these important ideas.
In Heptabase, our goal is to provide corresponding card types for all mainstream formats that carry knowledge, such as PDF cards, video cards, etc., so that they can not only be placed on the whiteboard, added with tags and properties, but users can also do highlight and annotation on them.
For example, Heptabase already supports PDF cards. Users can use text-selection or area-selection to pull out one Highlight card after another from the content of the PDF card and integrate these Highlight cards into the existing thinking context on the whiteboard. Users can not only write annotations on these Highlight cards but also locate them back to their original position in the PDF card with just one click.
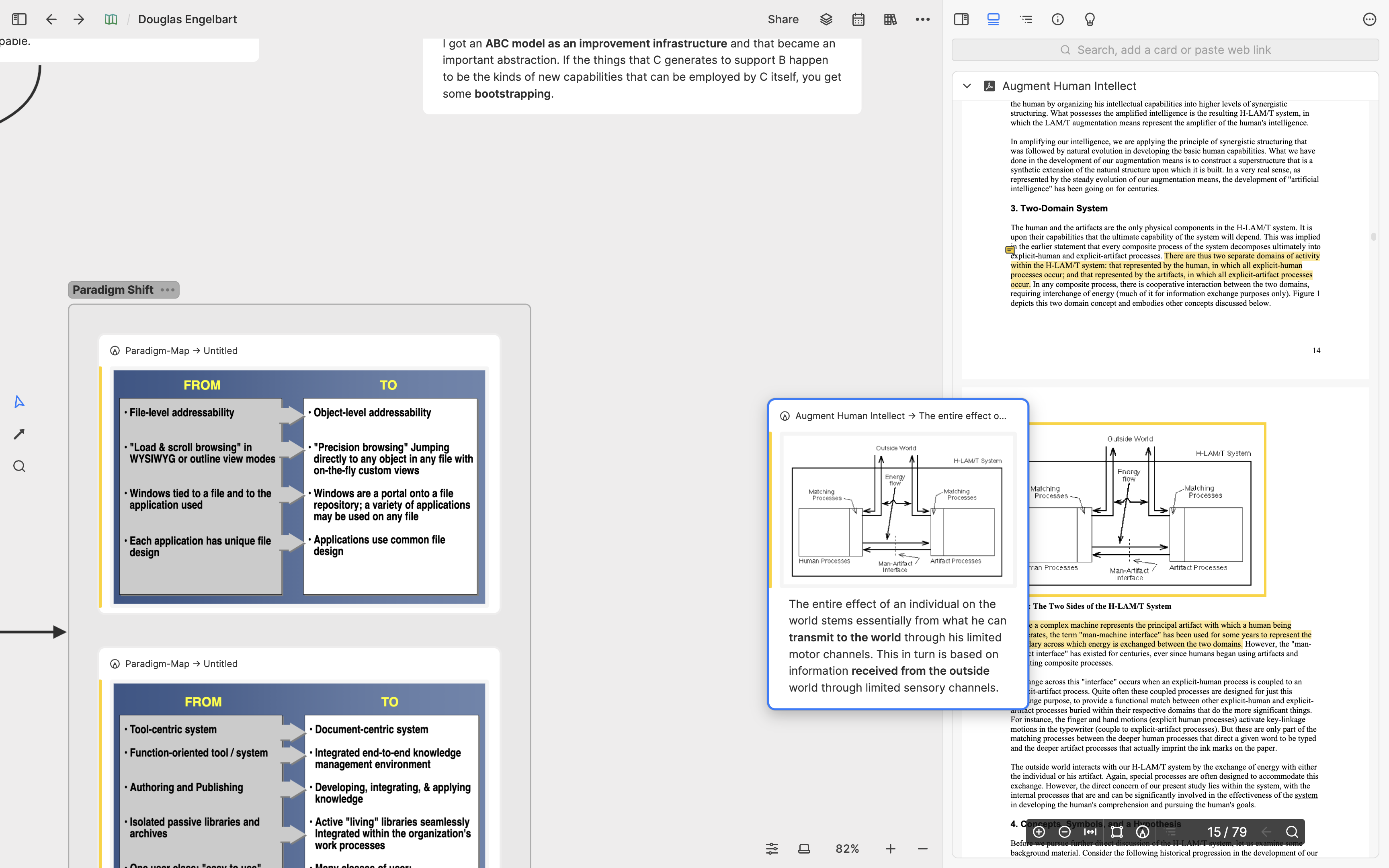
In the future, in addition to PDF, we will design and develop highlight and annotation functions for other data formats such as video, audio, images, and webpages, and all highlight and annotation will eventually use our annotation layer as a universal interface.
Integration Layer
In addition to files and static webpages, there is a lot of knowledge in this world saved in different products with special data structures. If we want to bring this type of third-party information into the Heptabase system, we must build interfaces that can synchronize with this third-party information, and create card aliases for this third-party information in Heptabase. This is the core task of the Integration Layer.
For example, if a user connects Readwise with Heptabase, all their Readwise Highlights will be instantly converted into Heptabase’s Highlight cards. If we develop Google Sheet integration in the future, we may support turning each row into a card, and specific columns will be written into the properties of the card.
Whether it is the annotation layer for annotating on static files or the integration layer for creating aliases for third-party data, their common goal is to bring external information into the user’s thinking context in Heptabase, allowing us to build a new contextualized knowledge internet on top of all existing human knowledge.
Stage 3 — Contextualize Collective Knowledge
In the first and second stages, Heptabase aimed to create the best “personal thinking tool.” However, starting from the third stage, we will build a communication tool on top of this thinking tool, allowing a group of users to collectively research complex topics, create collective knowledge, and bridge the “share → explore” gap in the knowledge lifecycle.
From the perspective of a knowledge internet, the task of this stage is to create a communication layer for knowledge.
Communication Layer
Before designing anything, we always need to think clearly about what problem this design is meant to solve. When people hear “communication software,” they may immediately think of messaging, commenting, collaboration, and co-editing. However, from the designer’s perspective, the “purpose and model of communication” is the most important thing that needs to be emphasized, rather than implementing these functions.
In social media (e.g. Facebook, Twitter), the common communication model is expression-driven. People seem to be discussing a topic, but in reality, they are more often expressing themselves: What are my opinions and positions on a certain issue? Which group of people do I want to attract attention from?
In work software (e.g. Slack, Notion), the common communication model is conclusion-driven. People often discuss back and forth to determine: What is our decision? What do we need to complete at what time?
The design of each communication software is aimed at helping users achieve their goals more effectively. Therefore, social media has more functions related to expression and sharing, while work software has more functions related to task integration.
At Heptabase, we want to create a world where anyone can effectively establish a deep understanding of anything. We believe that true collective wisdom relies not on forcing everyone to reach a consensus immediately, but on allowing each individual to expand their own cognition through others, and to see how their ideas are developed in the context of other people’s thinking.
Therefore, the communication layer we create will be comprehension-driven. Our design goal is to enable multiple people (including AI) to effectively construct their deep understanding of a topic through discussion, learning, and research. The understanding established by this group of people on this topic can be further expanded by other explorers in different contexts. When you want to learn a topic today, you no longer have to find isolated knowledge as in the past, but can explore the knowledge framework established by a group of people in the process of discussion.
Stage 4 — Contextualize Application Ecosystem
In the fourth stage, which is the final stage of the roadmap, our goal is to enable people to build different software on top of Heptabase, using these software to study different systems (physics, chemistry, biology, finance, mechanics, architecture, business, etc.), and create powerful knowledge representation for studying these systems. People can communicate, share, and modify the representations they create on our platform. They can establish a deep understanding of different fields using these representations while preserving the application context of the same knowledge in different representations across different software.
From the perspective of a knowledge internet, the task of this stage is to create an Application Layer for knowledge.
Application Layer
Regarding the specific implementation of Heptabase’s Application Layer, it would take another entire article to explain it clearly, so I will only briefly mention some core concepts here.
Unlike traditional software development, Heptabase will create an Application Layer that allows users to use cards on the whiteboard to build and assemble the interface of the software. Cards will no longer just be for taking notes, but users will also be able to write programs on cards and communicate with other cards (e.g. read property values of surrounding cards), or integrate with third-party databases, and ultimately present the data they want to display in the representation they choose on the card. Each card will be both an interface that users can directly see and manipulate, and a piece of code that users can directly adjust the logic of. A whiteboard and all the cards on it will add up to a software that users build themselves.
This kind of software development environment will not only allow users to directly manipulate the software they build on the production end, but also allow them to share the cards they make with other users, so that other users can use these cards as basic modules to assemble software with other purposes. Everyone can be both a user and a developer of software at the same time. Creating software will no longer be a commercial activity, but an activity that people use to study and understand different systems.
Once Heptabase creates an Application Layer that allows users to build customized software on the whiteboard, the use case of our knowledge internet will be able to expand to a much wider range of scenarios. For each knowledge card, users will be able to use its properties to trace where and how it is used and presented in other software built by different users, and thus establish a deeper understanding of this knowledge. This level of information interoperability and context tracing is unprecedented on the current internet.
Conclusion
In summary, Heptabase want to create a contextualized knowledge internet that allows everyone in the world to effectively establish a deep and comprehensive understanding of anything they want to learn or research.
This contextualized knowledge internet needs to be supported by a new open hyperdocument system, which will include many layers of infrastructure: the contextual layer for preserving thinking context, the descriptive layer for managing categories and adding properties, the annotation layer for annotating static files, the integration layer for creating aliases for third-party data, the communication layer for enabling a group of people to construct a deep understanding of complex topics, and the application layer for allowing users to build card-based software, and so on.
From an engineering perspective, we know clearly that such a complex system cannot be built in a short period of time. From a business perspective, we also know clearly that no matter how good our system is, if it does not solve real-world problems, no one will use it. Therefore, at Heptabase, we adopt a market-driven R&D logic, using continuous product iteration and extensive conversation with users to understand the market, and then creating a roadmap for building this system based on our understanding of the market and users.
Whether you have used Heptabase or not, we hope this article can help you better understand Heptabase’s vision and the positioning of our product in this vision. We will continue to work hard to make Heptabase evolve and realize our vision of creating a contextualized knowledge internet.
Photo by Matt Duncan / Unsplash
這篇文章是由 Heptabase 的共同創辦人詹雨安於 2023 年 5 月 1 日發布,當時 Heptabase 公測 Beta 版已發布一年左右。
Foreword
距離發表上一篇 My Vision 系列的文章已經一年半了。之所以會花這麼久的時間才寫下今天這篇文章,是因為我認為只有在與真實世界的用戶有大量的互動後,才能將願景中較為模糊的部分看的更加透徹。因此在過去一年半,Heptabase 團隊每天都在打造產品、與用戶對話,透過持續地迭代來驗證我們的假設。
在上一篇文章的結尾,我將 Heptabase 的願景描繪如下:
總結來說,在「知識的生命週期」這個維度上,我們希望能透過 Heptabase 的工具來幫助全世界的知識工作者打通「探索 → 收集 → 思考 → 創作 → 分享」的知識生命週期,讓資訊具備原生的互用性、讓想法的脈絡可被追蹤、讓集體知識的創建更為容易,進而演化出一個脈絡化的知識網路。
用這樣的方式來描繪願景,好處是它給出了一套知識生命週期的框架來指引我們的產品開發,以及三個在執行上要注意的大原則。然而對一般人來說,看完這段描述後心中仍會有許多疑問。
首先,我雖然在上一篇文章針對資訊互用、脈絡回溯和集體知識創建各自提出了一些想法和方向,但我並沒有真正深入地去談我們在執行層面上的路線圖。
再者,這個願景的描述較為抽象、學術,在看完後你可能還是會有點困惑:為什麼我們需要一個新的知識網路?保存想法的脈絡能為我們帶來什麼好處?Heptabase 的知識網路想解決的是人類的哪一個原始需求?
在今天這篇文章中,我會針對這些在上一篇文章沒有回答清楚的問題做深入地探討,講清楚 Heptabase 的核心目標,也讓 Heptabase 的用戶們更加暸解我們執行的路線圖。
Purpose
在討�論執行的路線圖之前,我想先重新用一種更白話的方式描繪 Heptabase 的願景:我們希望打造一個任何人都可以有效地對任何事物建立深度理解的世界。
在 Google、Social Media、ChatGPT 主導的資訊爆炸時代,獲取知識早已變得極為容易,但這些知識往往只是人類龐大的知識架構與思考脈絡中的冰山一角,而大多數人仍然對這些冰山的實際樣貌一無所知,深度理解複雜事物的能力也並沒有顯著的提升。
在 Heptabase,我們相信現代人在學習、研究和解決問題上遇到的最大困境並不是缺乏知識,而是缺乏將無數個單點知識串連起來的脈絡,以及建構並保存這些脈絡的工具。如果我們能為知識保存脈絡,並且讓全人類共享這些知識的脈絡,當其他人想學習和研究相同的知識時,就能利用這些知識的脈絡來建立更加全面且深入的理解。
在這樣的一個願景之上,我為公司的發展設定了四個漸進的階段。這四個階段的意義在於打造一個可以乘載脈絡化知識網路的「開放超文本系統」,並在每一個階段將這個系統需要的基礎建設一層層的搭建起來。以下我會詳細地討論這四個階段的目標與挑戰,並將這個系統的樣貌更完整的描繪出來。
Stage 1 — Contextualize Your Brain
在第一階段,我們的目標是打造一個幫助每個人學習和研究複雜主題的思考工具。這個工具的核心任務是讓用戶可以在大量資訊之上建構思考框架、提煉重要的想法與知識,打通知識生命週期中「收集 → 思考 → 創作」的環節,並且保存用戶大腦針對這些主題的思考脈絡。
從最終要打造的知識網路來看,這個階段的意義在於打造兩個基礎建設:Contextual Layer 和 Descriptive Layer。
Contextual Layer
在 Heptabase 中,乘載想法與知識的基礎單位是卡片,而 Contextual Layer 就是用來替這些卡片保存思考脈絡的 Layer,對應到的就是 Heptabase 的白板功能。沒使用過 Heptabase 的人光看外觀可能會覺得白板的用途是視覺化,但其實視覺化只是一種手段,它的真實用途是讓每一張卡片都可以追溯到它在不同白板下的思考脈絡。
也正是基於這個原因,我們在開發白板的初期,並沒有花太多時間在打造白板產品常見的手寫、形狀、線條、樣式等功能,而是專注在開發卡片在多重白板的復用、卡片與所在白板的雙向鏈結、白板與白板之間的階層架構、白板中知識卡片的分群與索引、卡片編輯器與白板之間的交互等與「保存知識脈絡」相關的功能。
Descriptive Layer
第一階段要打造的的第二個基礎建設是卡片的 Descriptive Layer,也就是負責給卡片添加類型與屬性的 Layer,對應到的就是 Heptabase 的 Tag 和 Property 功能。
在 Heptabase 裡,你可以對卡片添加不同的 Tags,並為這些 Tags 規定性質不同,但可以被不同 Tags 重複使用的 Properties。舉例來說,我透過 #research-note-taking 和 #research-communication 這二個 Tags 來管理我研究筆記軟體和溝通軟體的相關卡片,因為他們都是與研究有關的�卡片,因此可以共享 Document Type、Insight、Importance 這些與研究相關的 Properties。
對個人用戶來說,這樣的功能可以幫他們更好地用資料庫的形式一目暸然地管理同質性高的卡片,甚至像常見的專案管理系統一樣建立不同的 View 與 Filter 來用不同視角(例:表格、看板)觀看這些卡片。
當然,正如同白板的用途不單純是視覺化,Tag 和 Property 的用途也不單純是管理卡片。它們真正重要的長期用途是在第四階段時,可以讓第三方開發者在 Heptabase 的卡片系統上針對不同場景打造不同的軟體,進而拓展這些知識卡片可被復用的場景與脈絡。
Stage 2 — Contextualize Outer Sources
當 Heptabase 在第一階段已經打造出一個「足夠好」的思考工具時,我們就會進入第二階段,幫助用戶不只能保存自己大腦的思考脈絡,也能將外部資訊帶進這個脈絡一起思考,打通知識生命週期中「探索 → 收集」的環節。
從知識網路的角度來看,這個階段的意義在於打造兩個負責將外部資訊整合到 Heptabase 系統的基礎建設:Annotation Layer 和 Integration Layer。
Annotation Layer
在當今的網路世界中,有非常多的知識是被以 PDF、影片、音訊、圖片、網頁等不同的格式保存。如果我們�要打造能追溯脈絡的知識網路,我們勢必得將這些不同格式的知識整合進我們的知識網絡,讓用戶不只能從它們身上提取重要的想法,還能追溯這些重要想法的源頭。
在 Heptabase,我們的目標是對所有主流乘載知識的格式提供對應的卡片類型,像是 PDF 卡片、影音卡片等等,讓它們不只可以被放到白板上、被添加 Tag 和 Property,用戶還可以對它們做 Highlight 和 Annotation。
舉例來說,現在的 Heptabase 已經支援了 PDF 卡片。用戶可以在閱讀 PDF 卡片的過程中,透過文字選取或區域框選,從 PDF 的內容拉出一張又一張的 Highlight 卡片,將這些 Highlight 卡片放在白板上與既有的思考脈絡整合。用戶不只可以在這些 Highlight 卡片上寫註解,還可以從 Highlight 卡片一鍵定位回它在原始的 PDF 卡片中的位置。
在未來,除了 PDF 以外,我們將為影片、音訊、圖片、網頁等其他不同的資料形式設計並開發屬於它們自己的 Highlight 和 Annotation 功能,而所有的 Highlight 和 Annotation 最終都會使用我們的 Annotation Layer 作為通用介面。
Integration Layer
除了檔案與靜態網頁以外,這世界上有非常多知識是被用特殊的資料結構保存在不同的產品裡頭的。如果要將這種類型的第三方資訊引進 Heptabase 的系統,我們就必須打造能和這些第三方資訊同步的接口,為這些第三方資訊建立在 Heptabase 中的卡片替身(Alias)。這就是 Integration Layer 的核心任務。
舉例來說,如果用戶將 Readwise 與 Heptabase 對接,他所有的 Readwise Highlight 就會被即時的轉換成 Heptabase 的 Highlight 卡片。假設我們未來開發 Google Sheet Integration 的功能,則可能會支援讓用戶將每個 Row 變成一張卡片,而特定的 Column 則會被寫進這張卡片的 Property 裡頭。
不管是對靜態檔案建立註解的 Annotation Layer,還是對第三方資料建立替身的 Integration Layer,它們的共同目的都是將外部資訊整合進用戶在 Heptabase 中的思考脈絡,讓我們可以在人類所有的既有知識之上打造新的脈絡化知識網路。
Stage 3 — Contextualize Collective Knowledge
在第一和第二階段,Heptabase 都是以打造最好的「個人思考工具」為目標。但是從第三階段開始,我們就會在這個思考工具之上打造一個溝通工具,讓一群用戶可以共同研究複雜的主題、創建集體知識,打通知識生命週期中「分享 → 探索」的環節。
從知識網路的角度來看,這個階段的任務只有一個:打造知識的 Communication Layer。
Communication Layer
在做任何的設計之前,我們永遠都要先想清楚這個設計要解決的是什麼樣的問題。很多人在聽到「溝通軟體」時,第一時間可能會想到訊息、留言、協作、共編。但從設計者的角度來說,比起這些功能實作,「溝通的目的與模式」才是最需要被重視的東西。
在社群媒體中(例:Facebook、Twitter),常見的溝通模式是由「表達驅動」(Expression-driven)的。人們看似在討論,但其實更多時候是在表達自己:我對某個議��題的意見和立場是什麼?我想吸引哪個族群的關注?
在工作軟體中(例:Slack、Notion),常見的溝通模式是由「結論驅動」(Conclusion-driven)的。人們在一來一回的討論往往是為了確定:我們的決策是什麼?我們要在什麼時間完成什麼事情?
每一種溝通軟體的設計,都是為了幫助使用軟體的人更好的達成他們的目的,所以社群媒體有更多表達與分享相關的功能,而工作軟體則有更多任務整合相關的功能。
在 Heptabase,我們希望打造一個任何人都可以有效地對任何事物建立深度理解的世界。我們相信真正的集體智慧靠的不是強迫大家馬上達成共識,而是讓每個人都能藉由他人來擴充個體認知,看到自己的想法在別人的思考脈絡下會如何被展開。
所以我們所打造的 Communication Layer 會是「理解驅動」(Comprehension-driven)的。我們的設計目標是讓多人(包含 AI)在一起討論、學習、研究一個主題的過程中,每個人都可以有效地以這些討論的內容為原料,建構出他對這個主題的深度理解;而這群人對這個主題所建立的這些理解,可以被其他探索者進一步在不同的情境下擴充。當你今天想學習一個主題時,你不再像過去一樣只能找到單點式的知識,而是可以探索一群人在討論的過程中建立起來的知識架構。
Stage 4 — Contextualize Application Ecosystem
在第四階段,也就是路線圖的最終階段,我們的目標是讓人們可以在 Heptabase 之上打造不同的軟體,利用這些軟體來研究不同的系統(物理、化學、生物、金融、機械、建築、商業…)、創造適合用來研究這些系統的知識表達形式。人們可以在我們提供的平台上交流、分享、修改他們創造的表達形式,用不同的表達形式來對不同的領域建立深度的理解,同時又��能將相同知識在不同軟體的不同表達形式下的應用脈絡給保存下來。
從知識網路的角度來看,這個階段的任務是打造知識的 Application Layer。
Application Layer
關於 Heptabase 的 Application Layer 具體的實作方式,需要用另外一整篇的文章才有辦法講清楚,所以我這邊只會稍微提一些核心概念。
與傳統的軟體開發不同,Heptabase 的 Application Layer 會讓用戶可以在我們的白板上使用卡片來打造和組裝出軟體的介面。卡片不再只能記筆記,你還可以在卡片上寫程式和其他卡片溝通(例:讀取周圍其他卡片的 Property Value),或是和第三方資料庫對接,最終將你想呈現的資料用你選擇的表達形式在卡片上呈現出來。每一個卡片既是一個用戶可以直接看到和操縱的介面,同時也是一段用戶可以直接調整邏輯的程式碼,而一個白板和這個白板上面的所有卡片加總起來,就是一個用戶自己打造的軟體。
這樣的軟體開發環境不僅可以讓用戶在 Production 端直接用 Direct Manipulation 的方式來改動他打造的軟體,他同時還能將他做的卡片分享給其他用戶,讓其他用戶以這些卡片為基本的模組去組合出具備其他用途的軟體。每個人都同可以同時身兼軟體的用戶和軟體的開發者。創造軟體本身不再是一個商業化的行為,而是一個人們用來研究和理解不同系統的一種活動。
一但 Heptabase 打造出能讓用戶在白板上建立客製化軟體的 Application Layer,我們的知識網路就能拓展到更大的場景上。對於每一張卡片,你可以透過它的 Property 去追溯它在哪些軟體裡頭的哪��些場景下被用什麼方式呈現和使用,進而對這塊知識建立更深刻的理解。這種等級的資訊互用性和脈絡回溯的能力是我們在當前的網路上前所未見的。
Conclusion
總結來說,Heptabase 希望打造一個脈絡化的知識網路,讓世界上所有人都可以透過這個知識網路有效地對任何他想學習或研究的事物建立深度、全面的理解。
這個脈絡化的知識網路需要由一個新的開放超文本系統去支撐,而這個系統會包含許多層的基礎建設:保存思考脈絡的 Contextual Layer、管理類別與添加屬性的 Descriptive Layer、對靜態檔案建立註解的 Annotation Layer、對第三方資料建立替身的 Integration Layer、讓一群人可以共同對複雜主題建構深度理解的 Communication Layer、讓用戶可以打造基於卡片的軟體的 Application Layer 等等。
從工程上,我們非常清楚這樣複雜的系統是無法在短時間內打造出來的。從商業上,我們也很清楚不管我們打造的系統再怎麼好,如果它沒有解決真實世界的需求,就不會有人去使用它。因此在 Heptabase,我們採用的是一種由市場驅動的研發邏輯,透過持續的產品迭代以及與用戶的大量對話來暸解市場的樣貌,再根據我們對市場與用戶的理解來制定打造這個系統的路線圖。
不論你有沒有用過 Heptabase,我們希望這篇文章可以幫助你更加暸解 Heptabase 的願景,以及我們的產品在這個願景下的定位。我們將繼續努力,讓 Heptabase 不斷地進化,以實現我們打造脈絡化知識網路的願景。